Changeset View
Standalone View
keyserver/src/database/setup-db.js
| Show First 20 Lines • Show All 241 Lines • ▼ Show 20 Lines | SQL` | ||||
| confirmed tinyint(1) UNSIGNED NOT NULL DEFAULT 0 | confirmed tinyint(1) UNSIGNED NOT NULL DEFAULT 0 | ||||
| ) ENGINE=InnoDB DEFAULT CHARSET=utf8; | ) ENGINE=InnoDB DEFAULT CHARSET=utf8; | ||||
| CREATE TABLE siwe_nonces ( | CREATE TABLE siwe_nonces ( | ||||
| nonce char(17) NOT NULL, | nonce char(17) NOT NULL, | ||||
| creation_time bigint(20) NOT NULL | creation_time bigint(20) NOT NULL | ||||
| ) ENGINE=InnoDB DEFAULT CHARSET=utf8; | ) ENGINE=InnoDB DEFAULT CHARSET=utf8; | ||||
| CREATE TABLE search ( | |||||
| original_message_id bigint(20) NOT NULL, | |||||
| message_id bigint(20) NOT NULL, | |||||
ashoat: In the diff description, you say:
> When the message gets edited, this id will be updated to… | |||||
inkaAuthorUnsubmitted
Suppose we kept the id of the original message. When we run a full text search on this table, we only get the processed message, so we need to fetch the full message content form the messages table. To fetch the most recent edit, we would have to query for all messages with id or target_message matching the id and pick the most recent one. For the approach with changing the id in message_id column (and using the fact that we keep the old id as the primary key) the query would be something like: SELECT * FROM messages m JOIN search s ON s.original_message_id = m.id OR m.id = s.message_id WHERE MATCH(s.processed_content) AGAINST(query); And we would get the two messages for each match- the original and the most recent edit. But for the approach where we keep only the old id we would need to either run two queries to get the original and the newest edit separately, or have the query return all edits and handle that in js, or make one query return all originals but only the newest edits (I can only think of a way to do that that requires a nested SELECT: SELECT * FROM messages m JOIN search s ON s.original_message_id = m.id OR m.target_message = s.original_message_id WHERE MATCH(s.processed_content) AGAINST('friend') AND (m.target_message IS NULL OR m.time=(SELECT MAX(mm.time) FROM messages mm WHERE mm.target_message = m.target_message));) inka: > Can you clarify how / why it would be difficult?
>
Suppose we kept the id of the original… | |||||
ashoatUnsubmitted Thanks for explaining! ashoat: Thanks for explaining! | |||||
| processed_content mediumtext COLLATE utf8mb4_bin, | |||||
ashoatUnsubmitted Is processed_content a string tokens.join(' '), eg. looks like "after stemming / stop words" here? ashoat: Is `processed_content` a string `tokens.join(' ')`, eg. looks like "after stemming / stop… | |||||
inkaAuthorUnsubmitted Yes inka: Yes | |||||
| FULLTEXT(processed_content) | |||||
ashoatUnsubmitted What does this do? Does it create a new column, or is it a modifier on an existing column? Should it be given a name? ashoat: What does this do? Does it create a new column, or is it a modifier on an existing column? | |||||
inkaAuthorUnsubmitted It is a modifier on an existing column. It can be given a name, but this also works - it gives the index the name of the column. This is how it's done in docs. Should I give it a name anyway? inka: It is a modifier on an existing column. It can be given a name, but this also works - it gives… | |||||
ashoatUnsubmitted It looks like in the codebase we have a convention to name all indices. Can you give it a name? ashoat: It looks like in the codebase we have a convention to name all indices. Can you give it a name? | |||||
ashoatUnsubmitted It doesn't appear that you responded to this feedback? ashoat: It doesn't appear that you responded to this feedback? | |||||
| ) ENGINE=InnoDB DEFAULT CHARSET=utf8; | |||||
ashoatUnsubmitted Should we use utf8mb4 like we use elsewhere? I think it has some better behavior for emojis or something, I don't recall exactly ashoat: Should we use `utf8mb4` like we use elsewhere? I think it has some better behavior for emojis… | |||||
inkaAuthorUnsubmitted I suppose I should use the same value as for messages table, yes. utf8mb4 can store 4-byte chars, that include musical symbols, some historic alphabets, some emoji’s and some other symbols. inka: I suppose I should use the same value as for `messages` table, yes. `utf8mb4` can store 4-byte… | |||||
inkaAuthorUnsubmitted Although the natural library treats everything not in [a-zA-Z0-9] as a separator, so emojis are not indexed (source code) inka: Although the natural library treats everything not in [a-zA-Z0-9] as a separator, so emojis are… | |||||
ashoatUnsubmitted Thanks for investigating the natural library! Did you also investigate how the \W character class is treated specifically in Node.js's RegExp implementation? Wondering where you got the [a-zA-Z0-9] part ashoat: Thanks for investigating the `natural` library! Did you also investigate how the `\W` character… | |||||
inkaAuthorUnsubmitted I got it from regex page on wikipedia, and regex101. They both say that \W matches exactly to [^A-Za-z0-9_] but _ is added back by natural. It is also the same in MDN docs inka: I got it from [[ https://en.wikipedia.org/wiki/Regular_expression | regex page on wikipedia ]]… | |||||
ashoatUnsubmitted Please investigate how the \W character class is treated specifically in Node.js's RegExp implementation ashoat: Please investigate how the `\W` character class is treated specifically in Node.js's RegExp… | |||||
ashoatUnsubmitted I did some playing around with V8 and generally confirmed @inka's research. I didn't get to the point where I was able to precisely identify that \W matches [^A-Za-z0-9_]... instead, I gave up early after I found that the behavior isn't really what we want, eg.: 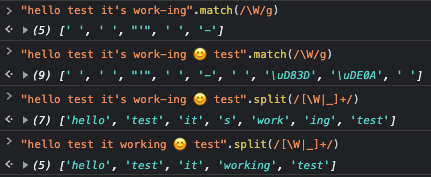 However, after some Googling and playing around I was able to get Intl.Segmenter to handle this in a much better way:  @inka, do you think we could use Intl.Segmenter for tokenization, and then the natural library for stemming? I'm open to patch-package on natural if necessary (but ideally perhaps we can avoid it). ashoat: I did some playing around with V8 and generally confirmed @inka's research. I didn't get to the… | |||||
ashoatUnsubmitted There also seem to be a variety of tokenizers available in the natural library. Can you clarify:
ashoat: There also seem to be a [variety of tokenizers](https://naturalnode.github. | |||||
inkaAuthorUnsubmitted natural.PorterStemmer.tokenizeAndStem uses AggressiveTokenizer by default (PorterStemmer gets this function from Stemmer that it extendes, and Stemmer uses AggressiveTokenizer). From the other tokanizers the only one that looks potentially useful for us is RegexpTokenizer, that allows to define own regex. const tokenizer = new natural.RegexpTokenizer({
pattern: /([A-Za-zÀ-ÿ-'"]+|[0-9._]+|.|!|\?|:|;|,|-)/iu,
});
console.log(tokenizer.tokenize(text));produces [ 'Hello', 'test', "it's", 'working', '😄', 'test' ] But it would be a bit difficult to have it parse it's as it's and 'hello' as hello. Generally we would have to come up with a good regex. The disadvantage of Intl.Segmenter is that there seems to be some problem with types: Intl is typed in flow builtin definitions, but it does not contain Segmenter https://github.com/facebook/flow/blob/main/lib/intl.js inka: `natural.PorterStemmer.tokenizeAndStem` uses `AggressiveTokenizer` by default ([[ https… | |||||
inkaAuthorUnsubmitted (sorry, was supposed to answer elsewhere, going to comment on D7077 as well ) inka: (sorry, was supposed to answer elsewhere, going to comment on D7077 as well ) | |||||
| ALTER TABLE cookies | ALTER TABLE cookies | ||||
| ADD PRIMARY KEY (id), | ADD PRIMARY KEY (id), | ||||
| ADD UNIQUE KEY device_token (device_token(512)), | ADD UNIQUE KEY device_token (device_token(512)), | ||||
| ADD KEY user_device_token (user,device_token(512)); | ADD KEY user_device_token (user,device_token(512)); | ||||
| ALTER TABLE days | ALTER TABLE days | ||||
| ADD PRIMARY KEY (id), | ADD PRIMARY KEY (id), | ||||
| ADD UNIQUE KEY date_thread (date,thread) USING BTREE; | ADD UNIQUE KEY date_thread (date,thread) USING BTREE; | ||||
| ▲ Show 20 Lines • Show All 100 Lines • ▼ Show 20 Lines | SQL` | ||||
| ALTER TABLE metadata | ALTER TABLE metadata | ||||
| ADD PRIMARY KEY (name); | ADD PRIMARY KEY (name); | ||||
| ALTER TABLE policy_acknowledgments | ALTER TABLE policy_acknowledgments | ||||
| ADD PRIMARY KEY (user, policy); | ADD PRIMARY KEY (user, policy); | ||||
| ALTER TABLE siwe_nonces | ALTER TABLE siwe_nonces | ||||
| ADD PRIMARY KEY (nonce); | ADD PRIMARY KEY (nonce); | ||||
| ALTER TABLE search | |||||
| ADD PRIMARY KEY (original_message_id), | |||||
ashoatUnsubmitted Did you actually test this like you claim in the test plan? I assume this comma is not valid SQL, so I'm confused as to how this didn't come up in your testing... ashoat: Did you actually test this like you claim in the test plan? I assume this comma is not valid… | |||||
inkaAuthorUnsubmitted I tested this diff as described in the test plan (that's how I encountered the problem with migrations), but I think I forgot to check the effects of this this last statement. Sorry inka: I tested this diff as described in the test plan (that's how I encountered the problem with… | |||||
| `, | `, | ||||
| { multipleStatements: true }, | { multipleStatements: true }, | ||||
| ); | ); | ||||
| } | } | ||||
| async function createUsers() { | async function createUsers() { | ||||
| const [user1, user2] = sortIDs(bots.commbot.userID, ashoat.id); | const [user1, user2] = sortIDs(bots.commbot.userID, ashoat.id); | ||||
| await dbQuery( | await dbQuery( | ||||
| ▲ Show 20 Lines • Show All 57 Lines • Show Last 20 Lines | |||||
In the diff description, you say:
Can you clarify how / why it would be difficult?