Details
- Tested if new chat mention regex works exactly like version with negative lookbehind assertions on web, iOS, Android.
- Checked if there are no errors in lib tests.
- Tested if error still occurs on Safari versions < 16.4 using BrowserStack.
Diff Detail
- Repository
- rCOMM Comm
- Branch
- patryk/remove-neg-lookbehind
- Lint
No Lint Coverage - Unit
No Test Coverage
Event Timeline
| lib/shared/mention-utils.js | ||
|---|---|---|
| 61 ↗ | (On Diff #31603) | https://stackoverflow.com/a/27213663. The one drawback of this solution is (?:[^\\\\@]|^) part (which is responsible for situations when user escapes @ symbol, (e.g. \@[[123:123]] should not match)) - it matches one char before @ symbol, that's why I had to add these weird if conditions in parseChatMention and renderChatMentionsWithAltText. |
Added @ashoat as a blocking reviewer since he's able to reproduce invalid group specifier name error.
| lib/shared/markdown.js | ||
|---|---|---|
| 238 ↗ | (On Diff #31603) | One thing to mention is that when caputre[0][0] !== '@' and we have access to the chat, this char at position 0 is not being bolded. |
| lib/shared/markdown.js | ||
|---|---|---|
| 238 ↗ | (On Diff #31603) | I'm not sure I understand what the change is that you're describing. Is it the case that the chat should be bolded when mentioned? If so, I'd like to understand the scenario you're describing better, and how it looks visually. It would be good if you could give some example inputs, and some screenshots of what the resultant behavior is |
| lib/shared/mention-utils.js | ||
| 61 ↗ | (On Diff #31603) | Hmm, I'm not sure this makes sense to me... It seems like you think [^\\\\@] is "anything other than the sequence \\@", but in fact it is "any character other than \, \, or @". It doesn't make sense to me why you're repeating the same character twice in a character class. Furthermore, I don't think it's your intention to support @ as an escape character... I think you just want \. Am I missing something?
I'm not sure I follow. It seems like you're saying that you have a problem because the match includes an extraneous character. In those cases, you should wrap the area you care about with a capture group. You can then always check for that capture group (by index, not by name – name is not supported in React Native). |
| lib/shared/markdown.js | ||
|---|---|---|
| 238 ↗ | (On Diff #31603) |  Since new regex catches one char before raw chat mention, I needed to make sure that the only part which is being bolded is raw chat mention only, we don't want to bold this one detected char before mention, right? Just wanted to add a comment which confirms that raw chat mention rendering behaviour hasn't changed. |
| lib/shared/mention-utils.js | ||
| 61 ↗ | (On Diff #31603) |
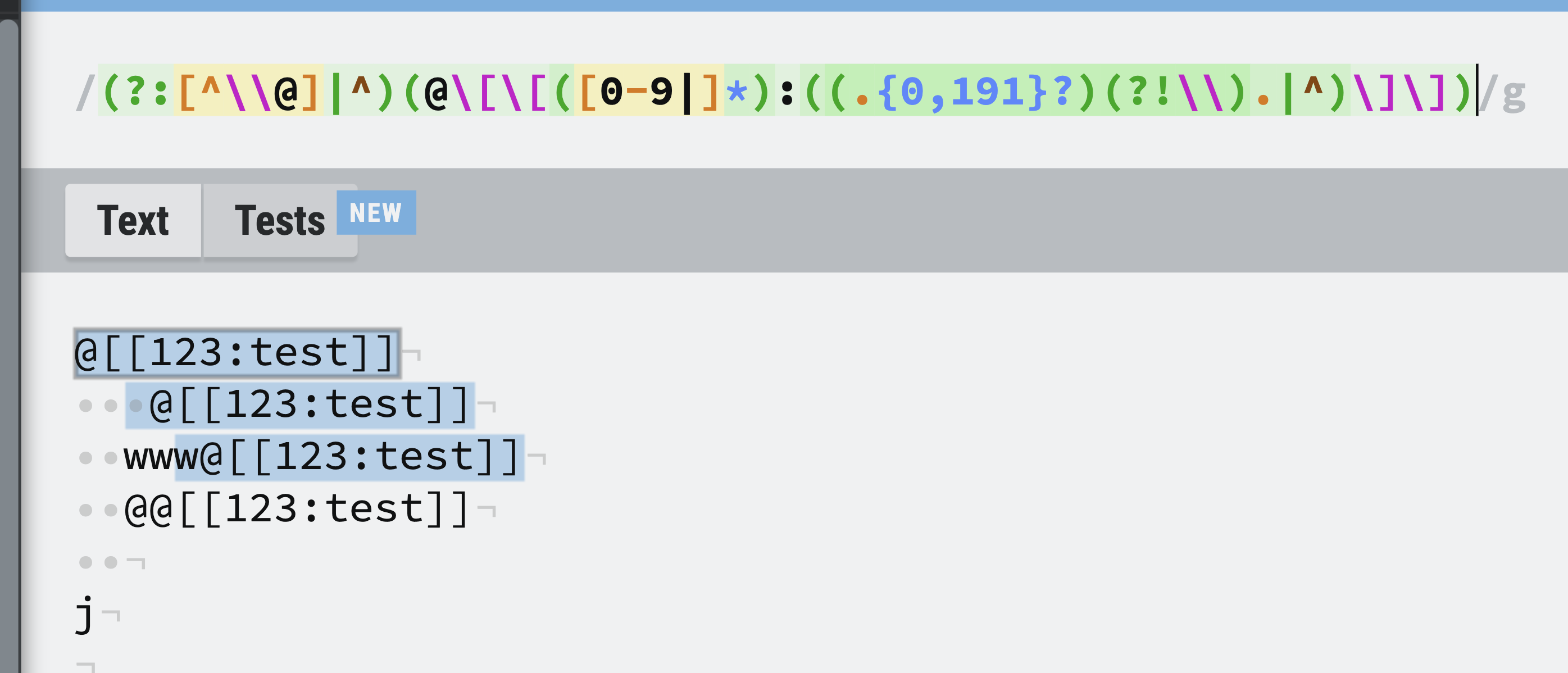 As you can see on photo above, this new regex also matches one char before valid chat mention. When we are "rendering" raw chat mentions, this one char should not be replaced by rendered chat mention (so we want to avoid a situation where user types e.g. w@[[123:123]] and it is replaced by @test and not by w@test). There are two special cases: what if user types @@[[123:123]] and what if we mention at the beginning of the text? When we start mentioning at the beginning, regex matches raw chat mention without first character before mention. How we should check if there is a character before valid chat? Well, I could check if match[0][0] !== '@' -> then I would know that regex has matched one char before raw chat mention. But what if we match @@[[123:123]]? if condition would indicate that matched string is a valid chat mention and it would render @123 rather than @@123. So I've added @ to the SET of invalid chars before raw mention. But, as you partially pointed out, this is not what we want to achieve -> This mention should not be invalidated since it is a proper chat mention. To handle this case, removing @ from [^\\\\@] and changing match[0][0] !== '@' condition to capture[0] === capture[1] ? '' : capture[0][0] solves the problem. WHY: capture[0] is a full match (with one char before raw chat mention), capture[1] is a match without this char before mention. Since the only case when we are not able to detect this char is when user mentions at the beginning of a text, we check if capture[0] === capture[1]. |
This diff was really hard to review. I wish somebody else could have done it, but @patryk's limited time to address his regression here (I was told that he had 4 hours) made me feel like I had to be personally involved in order to fix master and unblock releases again ASAP.
Separately, @patryk seemed to skip addressing one of my comments in the previous review:
It doesn't make sense to me why you're repeating the same character twice in a character class.
I'll address this myself. In fact, \\\\ represents a single \ character rather than two. The first layer of escapes is for the template literal, which results of \\ being passed to the RegExp. This represents a literal \ character, which is necessary to escape because a single \ character itself is used as an escape character in the RegExp.
| lib/shared/markdown.js | ||
|---|---|---|
| 238–240 | See below comment; this conditional should be replaced with a concatenation of two capture groups | |
| lib/shared/mention-utils.js | ||
| 78–84 | After playing around this locally, I think I understand what's going on here now. I'd like to propose an alternative:
(...match) => `${match[1]}@${decodeChatMentionText(match[4])}`This strikes me as far cleaner. | |
| lib/shared/markdown.js | ||
|---|---|---|
| 238 ↗ | (On Diff #31603) | Regarding bolding, let's keep behavior consistent with what we did for user mentions before your changes were shipped |
Thanks!! This looks clean, and I was able to confirm that it works on Safari version 15 running on macOS 12 via lambdatest.com