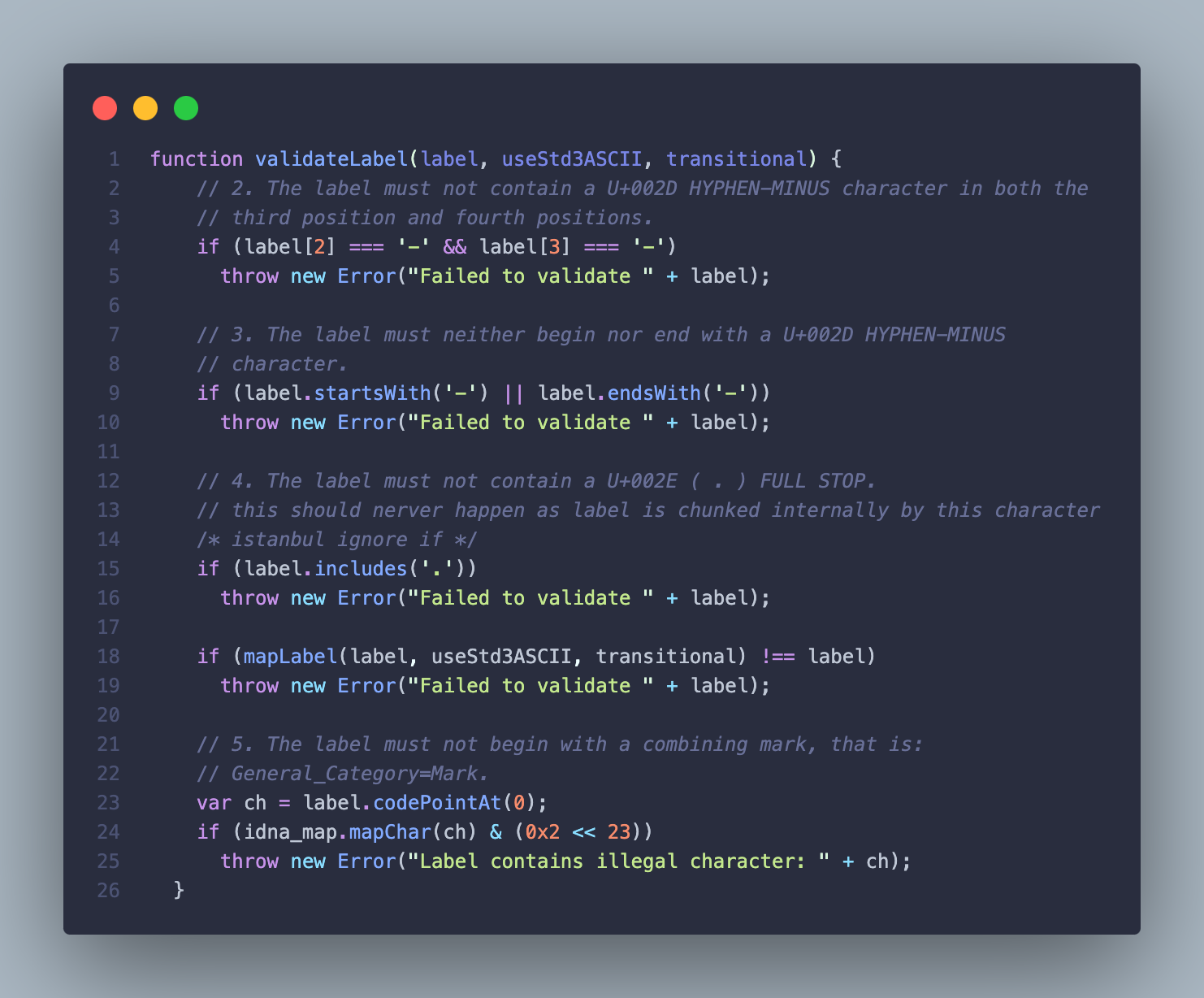
We perform two checks here to ensure the validity of an ENS name that is typed in the search experiences.
The first one is a general check to make sure the name adheres to the requirements listed in the Ethereum spec. Calling toAscii will throw an error if there is an invalid character, and at that point we can decide it's an invalid ENS name and not do anything special.
The second check is more specific and is a requirement we're enforcing to limit the number of name-to-address lookups that need to be done. We want to ensure that the TLD is .eth and the SLD has at least three characters, as that seems to be a general standard enforced by the ENS team for now. To do this, a regex pattern is easy enough to check on the input text. If there is a match, this means we have a valid ENS name typed out in the search, and only at this point do we want to do a forward lookup.