This differential implements a fetcher and an updater for olm accounts on the keyserver. All changes to olm account are done in-memory on olm.Account instance. Therefore the updater takes just olm.Account instance since all updates are already in this object and it just need to be
serialized and stored in database.
Details
Details
Find a place in the keyserver codebase to execute the following sequence:
- Use fetcher to get olm account.
- Change its structure by calling for example generate_prekey()
- Store it back by calling updater.
In each step use database inspection tool of choice, to examine that pickled account string in the database has changed.
Diff Detail
Diff Detail
- Repository
- rCOMM Comm
- Lint
No Lint Coverage - Unit
No Test Coverage
Event Timeline
There are a very large number of changes, so older changes are hidden. Show Older Changes
| keyserver/src/fetchers/olm-account-fetcher.js | ||
|---|---|---|
| 12 ↗ | (On Diff #25545) | Please stick to 80 char lines, and please format this like other SQL queries in our codebase |
| 17 ↗ | (On Diff #25545) | Can we make the error more clear if no result was matched? |
| keyserver/src/updaters/olm-account-updater.js | ||
| 15 ↗ | (On Diff #25545) | Same feedback about SQL query |
| keyserver/src/fetchers/olm-account-fetcher.js | ||
|---|---|---|
| 9 ↗ | (On Diff #25545) | It's unclear this boolean indicates at the callsite. Can we instead take something like this? olmAccountType: 'primary' | 'notifs', |
| keyserver/src/fetchers/olm-account-fetcher.js | ||
|---|---|---|
| 12 ↗ | (On Diff #25545) | FWIW the TablePlus "Beautify" command (⌘+I) and DataGrip "Format" command (⌘+⌥+L) format SQL queries with code style that pretty much matches ours 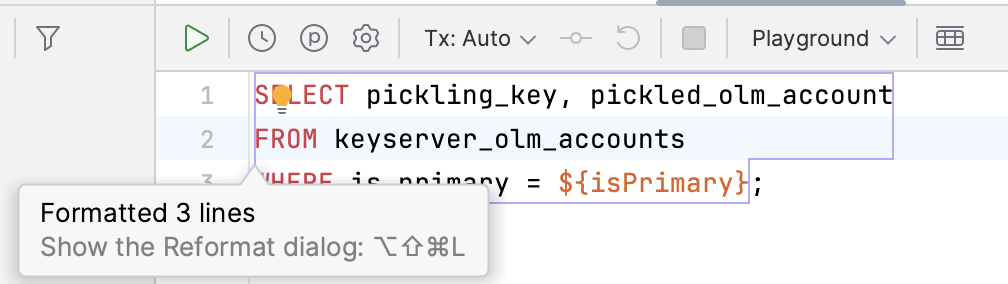 (they don't handle capitalization though) |
Comment Actions
When I say something like this:
and please format this like other SQL queries in our codebase
My intention is that you search through the codebase, figure out how SQL queries are formatted, and do it the same way. It's not a good use of my time or your time for us to keep going back-and-forth over minor nits on a diff like this. Ideally you do this work before even submitting a diff
| keyserver/src/fetchers/olm-account-fetcher.js | ||
|---|---|---|
| 12 ↗ | (On Diff #25596) | You only appear to use the first part of the result here. Why not do what we do everywhere else in the codebase, and only assign the first part, so you don't need to index into it at every callsite? |
| 16 ↗ | (On Diff #25596) | Please match conventions in the codebase. We always have spaces here, and we tend to skip the semicolons. It's the diff author's responsibility to look up and match existing conventions... it's not a great use of reviewer time to be pointing out simple things like this |
| 21 ↗ | (On Diff #25596) | Please don't throw raw strings like this. We don't do this elsewhere in the codebase, which should be a "red flag" for you. In general you should endeavor to match existing conventions in the codebase as much as possible, ideally without reviewers having to point it out to you I'm not sure if/where this will get called outside of cron.js (eg. will it get called from a responder?), but generally we prefer to use ServerError since it is handled better when thrown from inside a responder |
| keyserver/src/updaters/olm-account-updater.js | ||
| 15–17 ↗ | (On Diff #25596) | Fix these queries to match conventions in codebase |
| keyserver/src/fetchers/olm-account-fetcher.js | ||
|---|---|---|
| 21 ↗ | (On Diff #25596) | Next diffs in this stack will call it in a responder. |
Comment Actions
Address inline comment before landing, and please pay more attention to existing codebase conventions going forward
| keyserver/src/fetchers/olm-account-fetcher.js | ||
|---|---|---|
| 24 ↗ | (On Diff #25608) | You are still not matching conventions, which is particularly surprising since I gave a specific suggestion in my last review. I am sharing that exact same suggestion here; please apply it exactly |
Comment Actions
Merge fetcher and updater into one fuction that atomically (using transaction) updates olm account in the database by calling JS lambda.
Comment Actions
Removing some reviewers to avoid polluting their queues
| keyserver/src/updaters/olm-account-updater.js | ||
|---|---|---|
| 16–58 ↗ | (On Diff #25759) | As discussed in our 1:1, I'd like to avoid this pattern of having the START TRANSACTION in one query, and having the transaction closed in a separate query Instead, the plan was to have a single query that opens and closes the transaction The pattern should be "try to get the lock if possible, and if we get the lock then issue the SELECT query to get the data. if we can't get the lock, then we fail the query". If the query fails because somebody else has the lock, then the caller can simply sleep a bit and then try again If the query fails because the row does not exist, that should be handled separately. That could arguably be handled at the very start, before the transaction If you want to take a different approach, I am open to it, but you need to explain the tradeoffs and why you opted against the planned approach. Perhaps you felt the sleep was not great for performance (true), but we need to weigh that against the potential impact of locking the database while we issue multiple queries within a single transaction I'd also like to make sure @tomek takes a look here, as he is more of an expert on databases than I am |
| keyserver/src/updaters/olm-account-updater.js | ||
|---|---|---|
| 16–58 ↗ | (On Diff #25759) |
As far as I remember we didn't explicitly decide one the particular approach but kept it open for both. It doesn't really matter but I just want to note that I didn't deliberately acted against what we agreed on without providing some tradeoffs discussion. I thought I can follow whichever approach I found working. Basically the choice between my approach and yours comes down to a question, whether issuing plain START TRANSACTION query locks entire database while one query START TRANSACTION; SELECT...; UPDATE ....; COMMIT; makes database aware of what we are doing in the query so that it can optimize what is locked and what is not. Looks like it is really tough to find resources that answer this question. The most comprehensive material I found is this: http://dev.cs.ovgu.de/db/mysql/InnoDB-transaction-model.html. It states that locks on the database are on the row level. Additionally it states that InnoDB sets locks on the rows that it encounters when it scans the database as a results of executing query. In our dilemma there are no queries immediately after the START TRANSACTION so it doesn't have an information which rows to lock. It would be strange default behaviour to lock the entire database at once if there are no other queries. I understand we are looking for an explicit answer and the resources I found are not an explicit answer. However I couldn't find any resources suggesting that database might be locked by default if plain START TRANSACTION is issued.
I definitely thought about performance. But another thing to consider is that while() { sleep() } os an anti-pattern especially when dealing with databases which have decades of research to solve those kinds of problems for developers. Being an open source project we should avoid implementing solution that might look suspicious to the community. I will pursue looking for more explicit answer. Knowing we want to meet the monthly goal I will time box it. If I have no solution until the tomorrow's crypto sync (it is the middle of my working day) I will drop the research and go ahead with sleep and create follow up issue giving it high priority to revisit it quickly during the bug bash in the second half of may. My intuition on is that the best thing to do here is to create some source of worker process that operates sequentially by consuming some task queue, which is similar to what we have on native but on process level. I believe there must be some library to do so in JS. It is a common backed case and there are such libraries for other languages such as Celery for Python. Doing so however is out of the scope right now as we must meet the deadline. |
| keyserver/src/updaters/olm-account-updater.js | ||
|---|---|---|
| 16–58 ↗ | (On Diff #25759) | This is a tricky one and I don't exactly know how it works. But it sounds reasonable that the engine could use the whole query to optimize locking strategy and limit the locking to just some rows / tables. It also depends on the isolation level we have configured for our db - for the lowest isolation levels it shouldn't matter, but for higher there should be significant difference in performance. From the performance point of view, the locks will be acquired only for the duration of transaction, so if the transaction doesn't last for too long, even if it locks the entire database, it shouldn't have too high impact. Especially that every update / delete operation probably also locks tables, and we already have some delete queries which touch a lot of tables. One thing about locking is that it isn't necessary as bad as it sounds, because transactions usually are implemented as hidden columns where transaction ids are stored. So the operation isn't blocked and is executed, and then later, when it gets committed, the ids are updated. Disclaimer: most of this isn't based on any research, just on the things I remember, which may not always be accurate and depends heavily on the engine. I can spend some time doing the research, if we think it makes sense. |
| keyserver/src/updaters/olm-account-updater.js | ||
|---|---|---|
| 12 ↗ | (On Diff #25759) | We should use Promise<mixed> here since we don't care about the return type. Basically we always probably () => mixed over () => void when typing a parameter, since usually the latter means we don't care about the return |
Comment Actions
Return mixed. Add method to fetch account in non-blocking fashion for read-only purposes.
Comment Actions
The feedback regarding the transaction remains unaddressed. I had described an approach for doing this over a week ago. You said you were going to timebox the investigation of your proposed alternative. Is this still something you want to pursue? This is blocking the rest of your stack, and I wonder how much faster we could have landed this if you took the initially proposed approach...
Comment Actions
Implement spinlock with update versioning to mitigate race condition when updating olm account table
Comment Actions
Thinking more about the approach with boolean lock I realised it has a vulnerability. If we successfully acquire the lock, but then the error occurs before we update olm accounts table and release the lock, the table will be unusable until someone manually types SQL query to the database. The address this issue I propose versioning approach. Basically instead of boolean lock column we have integer version column. When someone want to update olm account they read its current version along with pickled data and pickling key. Then they do their operations on data in JS memory and attempt to update olm account table with new pickled data. Inside a transaction that updates data they first read the current version of the row. The update occurs only if the version matches the one their read during the first query. If it doesn't no update occurs and they retry. This way olm account table will never be unusable.
Comment Actions
Great work on this, @marcin – your approach is different from what I proposed, but I agree it is a better approach. Thanks for thinking about this!
Some minor comments inline – please address before landing.
| keyserver/src/updaters/olm-account-updater.js | ||
|---|---|---|
| 24 ↗ | (On Diff #26101) | Let's put the WHERE on its own line to match our existing conventions for writing SQL queries. I encourage you to try and research these conventions ahead of putting up diffs, as it will save both of us some time in the future |
| 52 ↗ | (On Diff #26101) | WHERE on its own line please |
| 64 ↗ | (On Diff #26101) | Can we remove this newline? |
| 76 ↗ | (On Diff #26101) | Can you extract this constant and put it next to maxOlmAccountUpdateRetriesCount? |
| keyserver/src/updaters/olm-account-updater.js | ||
|---|---|---|
| 12 | I decreased delay value following my discussion with @tomek . He reasoned that operations that take place inside a loop are fast and such high delay value like 2000ms decreases the chance that the caller of this method will be the very next to acquire the lock, while it should be the opposite. | |